Why we built it
Ship LLM features with repeatable evaluation—not demo-grade guesses—in production.
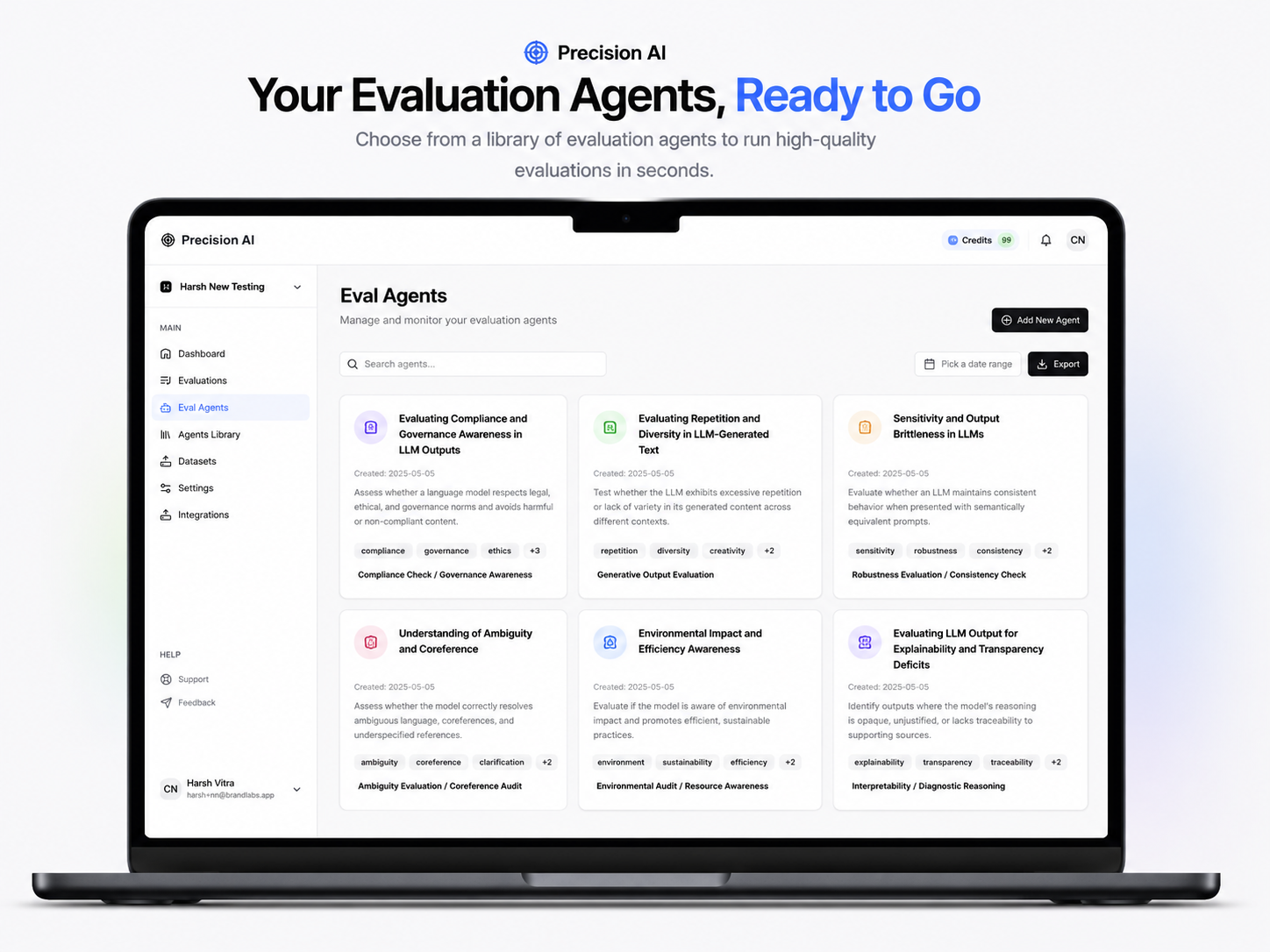
Problems we solve
Ship AI with a quality bar
Problem
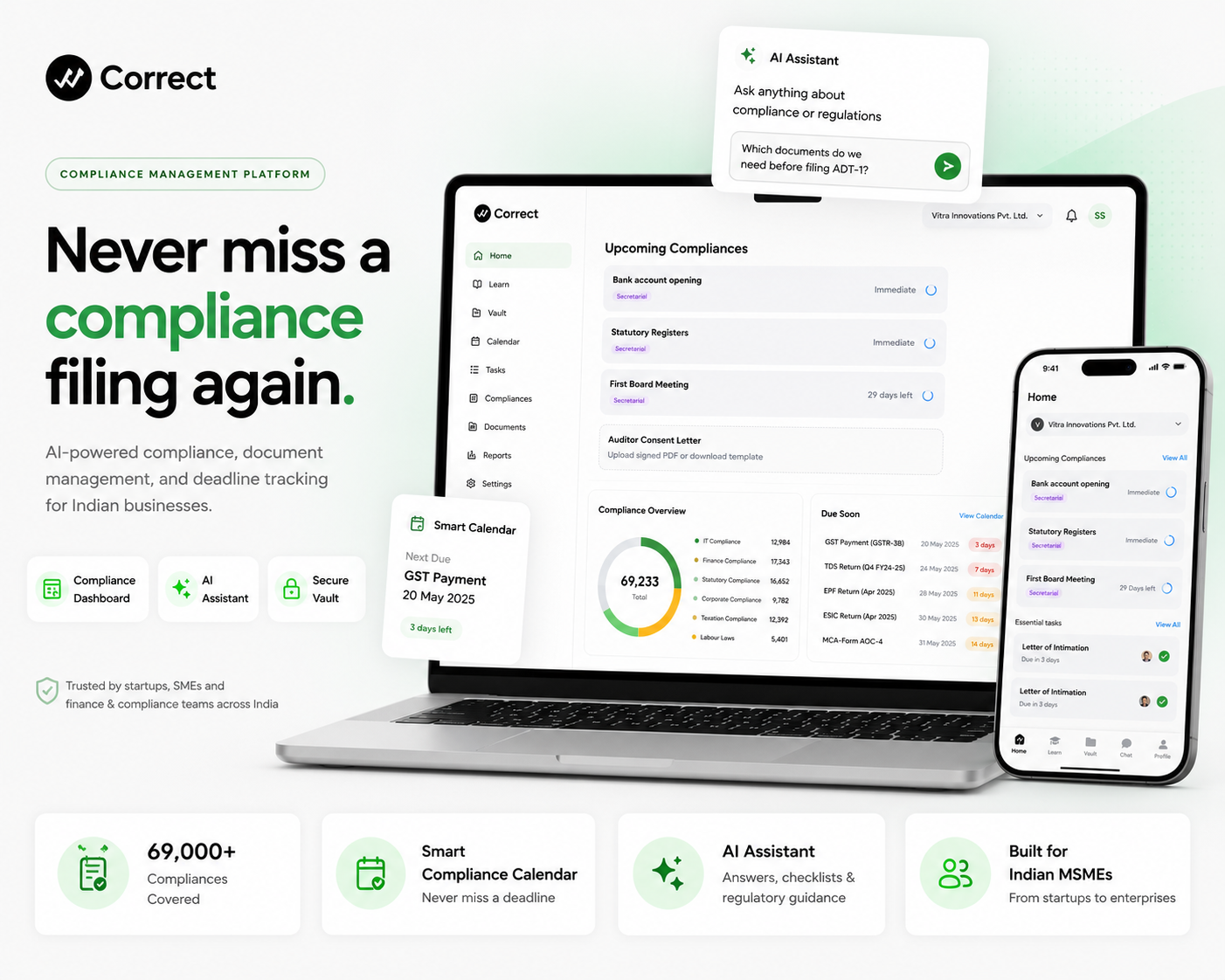
Product and engineering teams launch chatbots, copilots, and LLM features with no repeatable way to judge quality. “Looks fine in demo” turns into inconsistent, off-brand, or wrong answers in production—with no score, no rubric, and no paper trail.
How Precision solves it
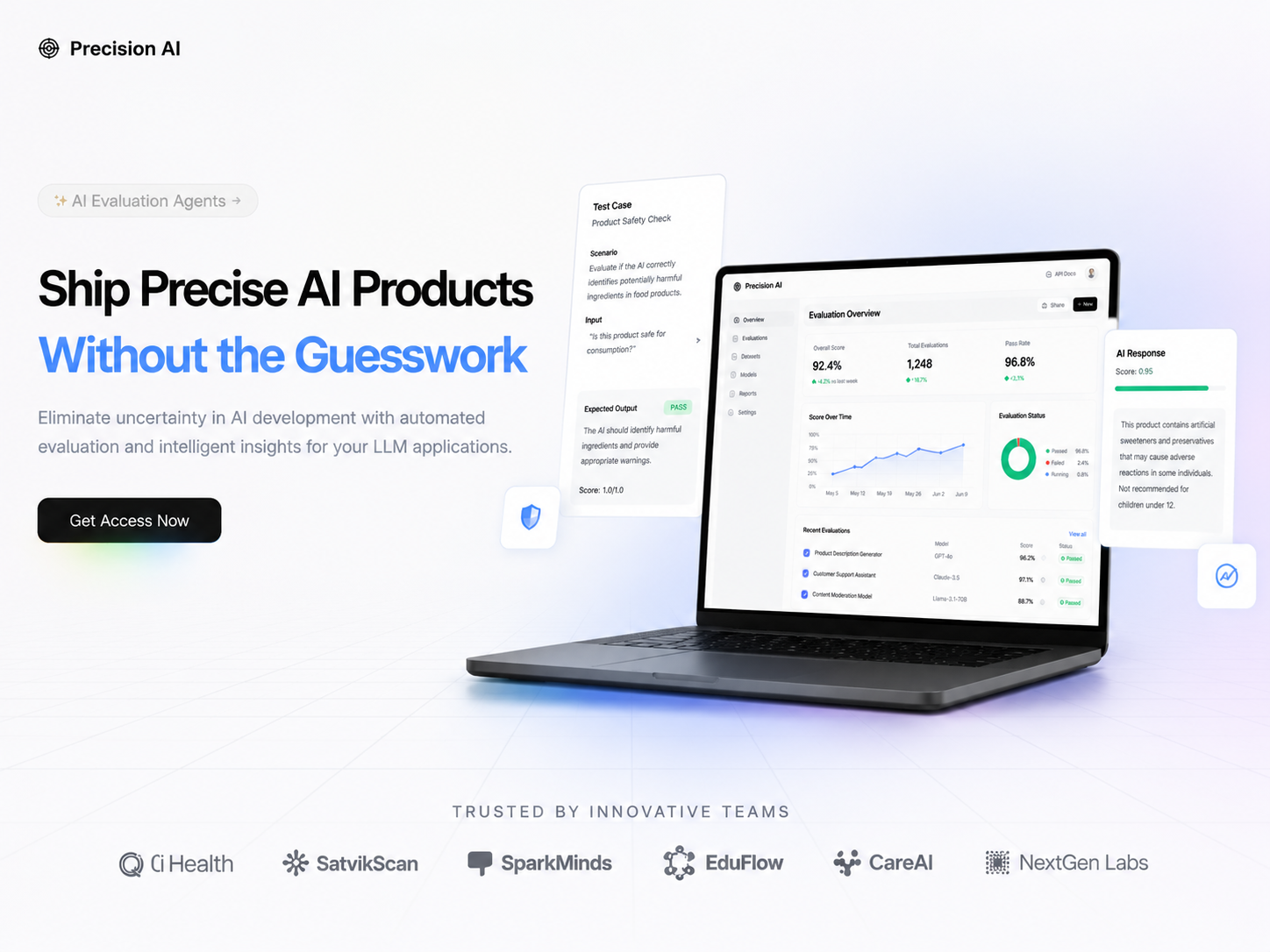
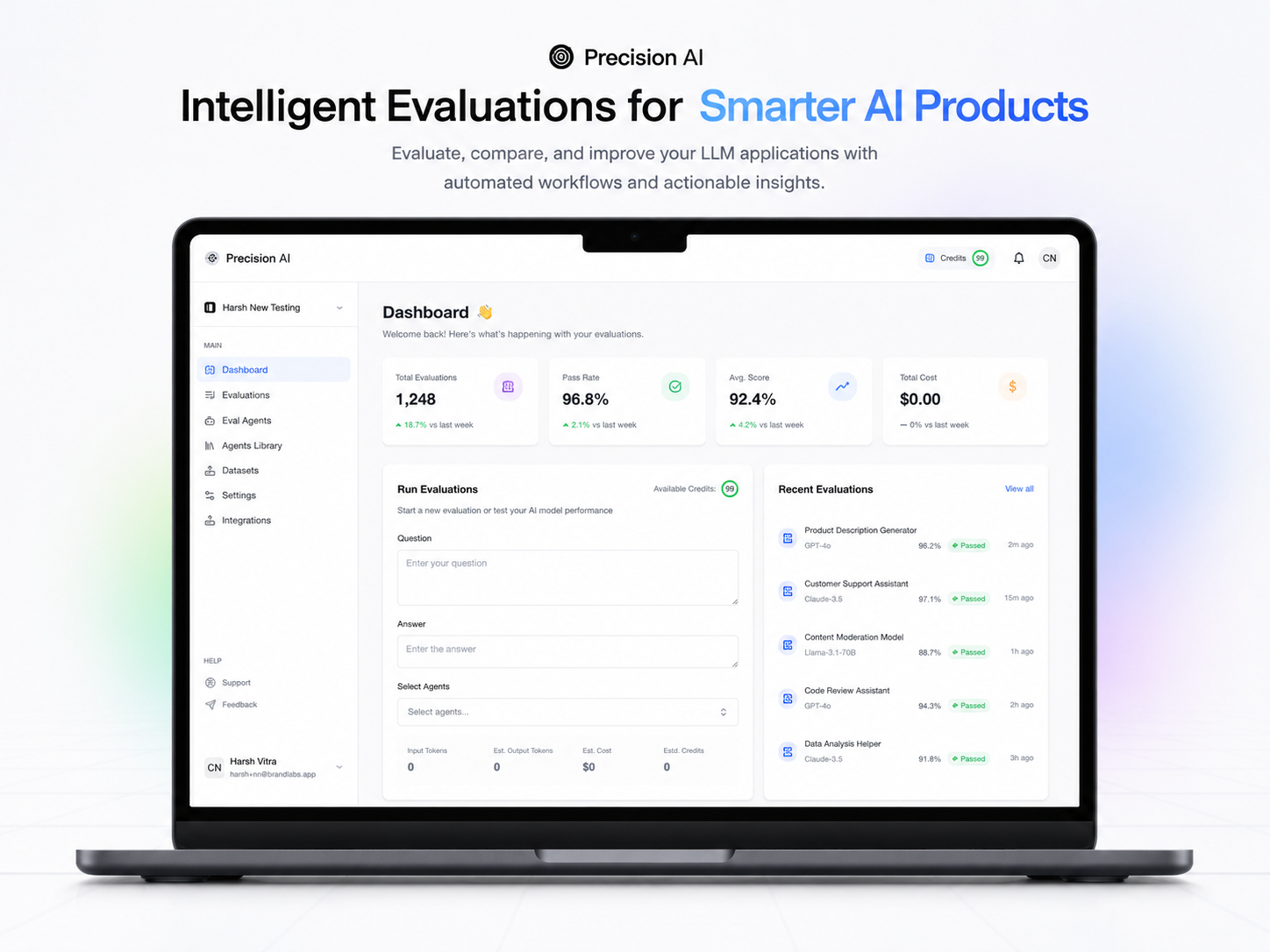
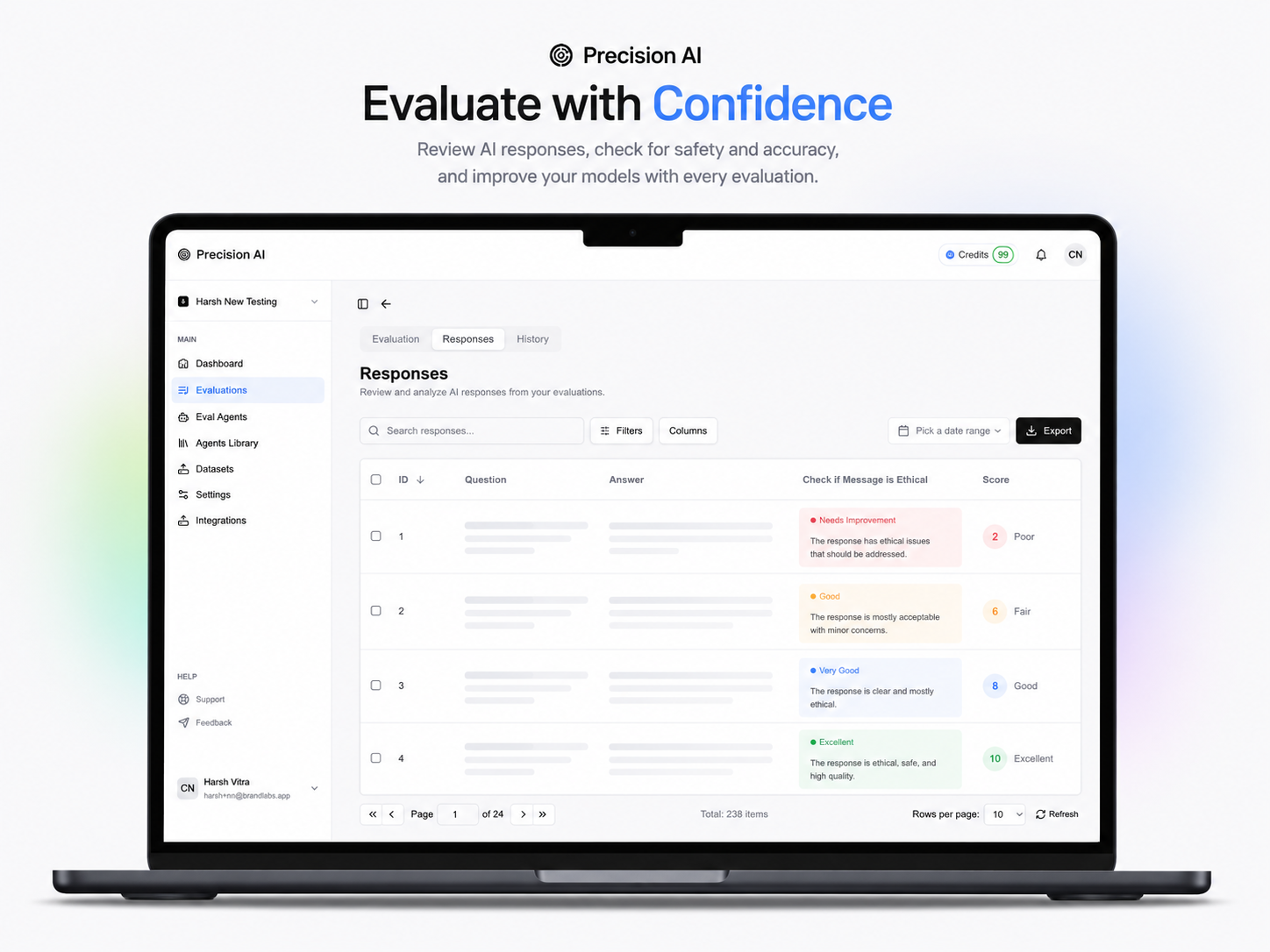
Organizations define evaluation agents with custom criteria (evaluationPrompt), plus sample good and bad responses as anchors. For each user question and model answer, Precision runs automated evaluation—0–10 accuracy, written analysis, and highlighted problem phrases. Results live in the dashboard under Evaluations, with Responses and History so teams can review, compare runs, and iterate on prompts and models instead of guessing.
Structured prompt feedback
Problem
Better prompts drive better outputs, but individuals and teams rarely get objective feedback on their questions and model replies. Trial-and-error in ChatGPT doesn’t transfer to production bots or team standards.
How Precision solves it
Precision treats prompting as something you evaluate and improve, not only something you type. Users run Q&A pairs through eval agents that explain what’s wrong and what “good” looks like via sample responses and analysis. The public Agent Library offers free, ready-made evaluation agents—so teams can practice and improve prompting without building rubrics from scratch. The Learn section and homepage blog cards keep education and product in one place.
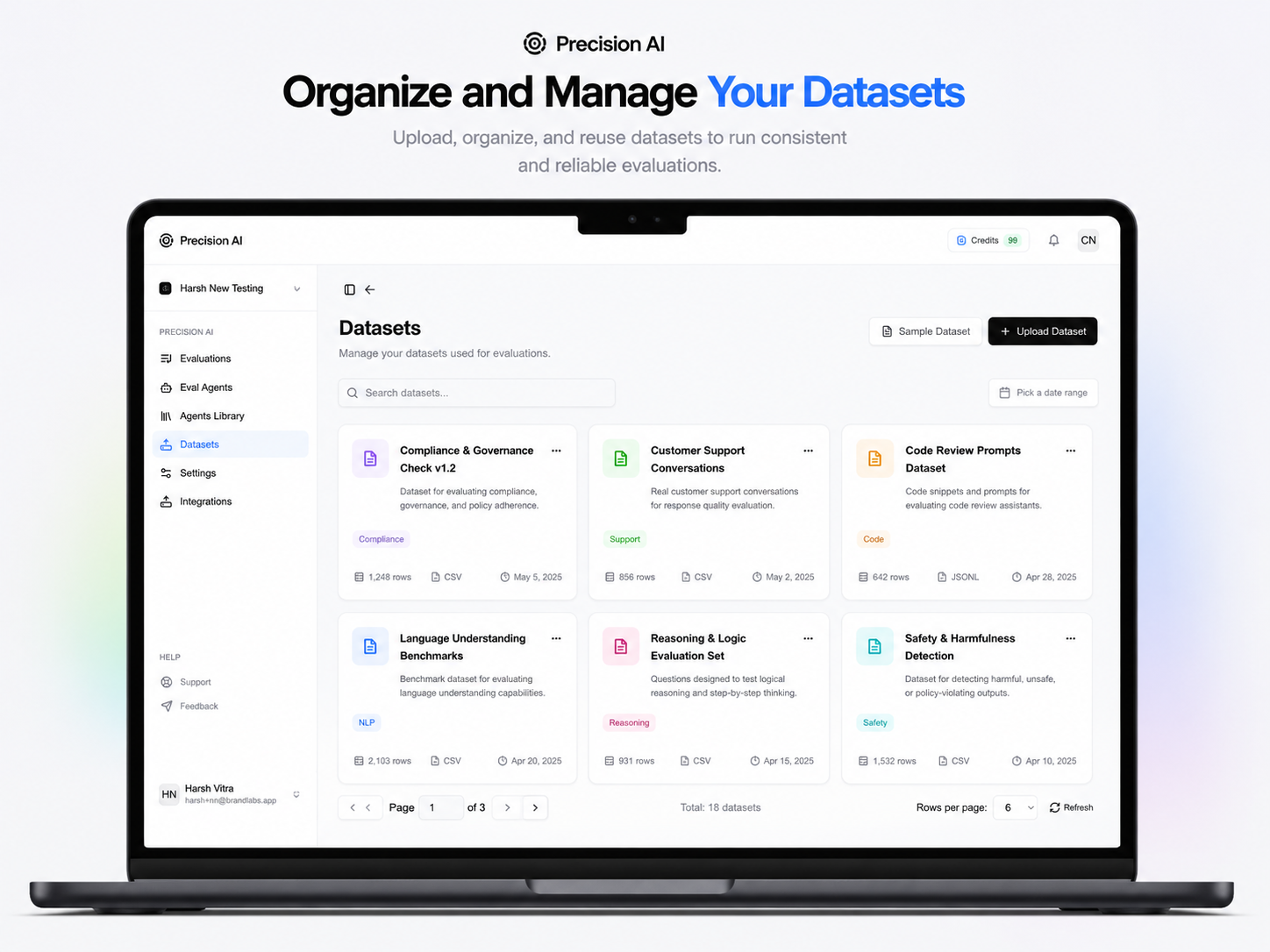
Evaluation at scale
Problem
Reviewing bot conversations one-by-one doesn’t scale for support bots, internal assistants, or RAG apps. Spreadsheets and spot-checks miss regressions when models, prompts, or data change.
How Precision solves it
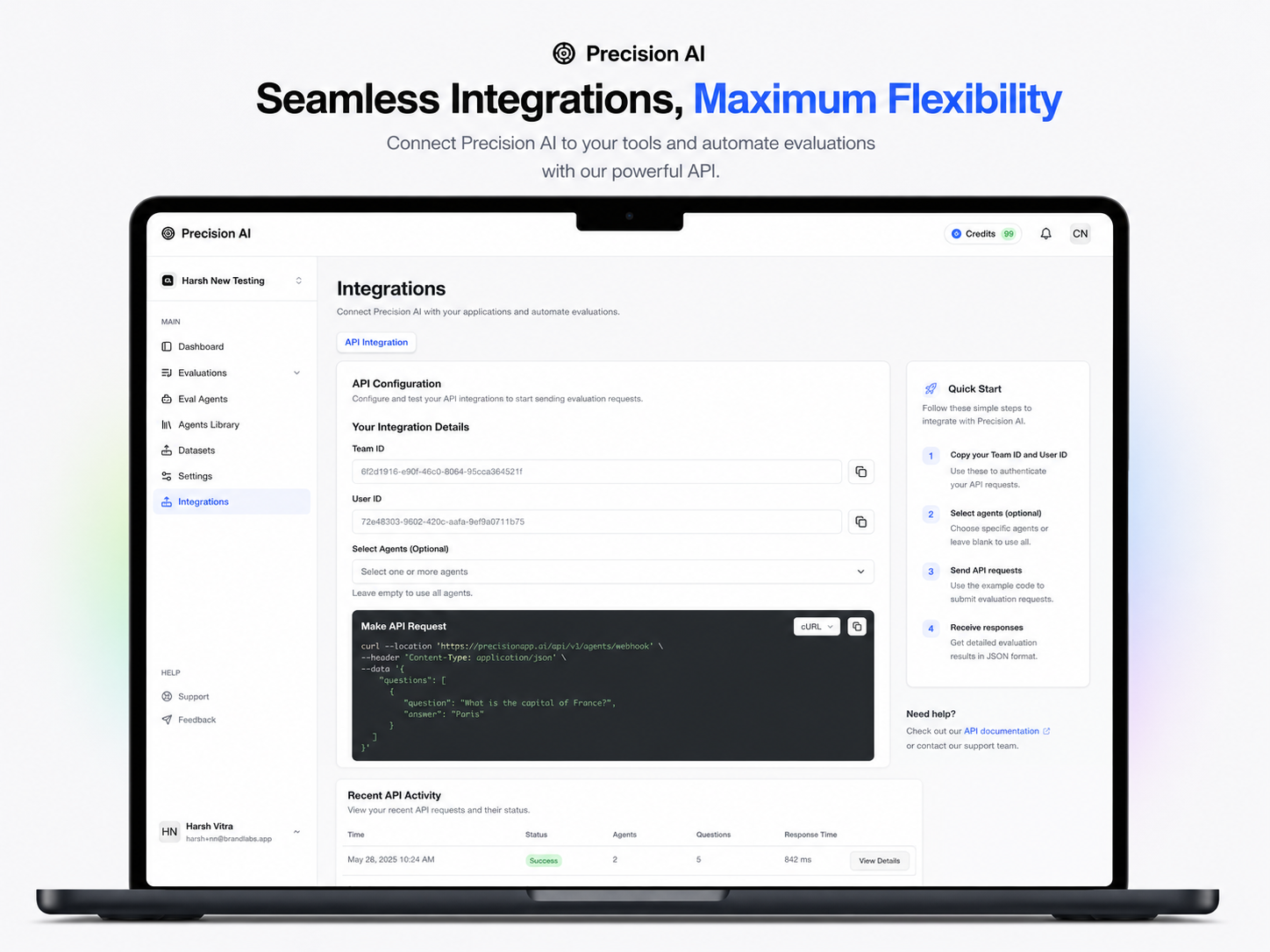
Teams upload datasets (CSV of question/answer pairs) and run bulk evaluation—including multi-agent runs across several evaluators at once. The webhook API batches work (e.g. 10 Q&A pairs at a time), ties runs to team and dataset, and supports integration into existing pipelines. Exports and evaluation tables help orgs track quality over time instead of re-reading every thread by hand.
One quality bar for the org
Problem
One person’s “good enough” isn’t another’s. Without shared tools, eval criteria, and history, teams duplicate effort, miss regressions, and can’t confidently improve bot models and system prompts together.
How Precision solves it
Teams are first-class: create and switch teams, shared Eval Agents, Datasets, and team-scoped evaluations and credits. Everyone works against the same evaluation agents and rubrics, so product, ops, and engineering share one definition of quality. Admins manage teams and members; eval agents can use your own API keys or platform credits—so the whole org improves bot behavior from the same evidence base.
Stay current while you ship
Problem
Models, APIs, and best practices change weekly. Teams lack a trusted, curated stream of practical updates—not just hype—and struggle to connect “latest news” to “how we evaluate and ship AI.”
How Precision solves it
The Learn hub publishes articles on AI evaluation, LLMs, and related tech, with search and archive. The landing page surfaces fresh posts via rotating blog cards, so Precision is both an evaluation product and an ongoing learning surface—helping users stay current while applying what they learn to real Q&A evaluation.
Outcome
Precision is live as an evaluation and learning platform: teams define rubrics, run single and bulk evals, review prompt-level feedback in the dashboard, align on shared agents and datasets, integrate via webhooks, and stay current through Learn and the Agent Library—replacing demo guesswork with measurable, repeatable LLM quality.